quaintitative
I write about my explorations in AI and other quaintitative areas.
For more about me and my other interests, visit playgrd, quaintitative or socials below
Categories
Building AI models for Learning User Interface Designs
The research for my PHD thesis focuses on the learning of dynamic multimodal networks. Ever since I selected this as my research area, I started seeing such networks everywhere around me.
One of the places where I found such networks is in the domain of user interfaces (UI) (the other is finance, which I will touch on sometime in the future). If you are familiar with either designing or coding a UI, you will probably realize that each UI is actually comprised of many different objects composed together. Objects could be UI elements such as text boxes or images, or even the text within the text boxes. UI objects do not exist in isolation. They share different relationships with each other, e.g., with applications that they are a part or; with their neighbouring elements; with elements within each of them. If you look at the figure below (extracted from my first paper on learning UI design networks), you will get an idea of the different inter-linked UI elements in a UI screen.

Since this first paper that was titled Learning Network-Based Multi-Modal Mobile User Interface Embedding, where I proposed a relatively simple model based on combining graph neural networks and variational inference, I have expanded my thinking on how such networks could be composed (and hence extracted).
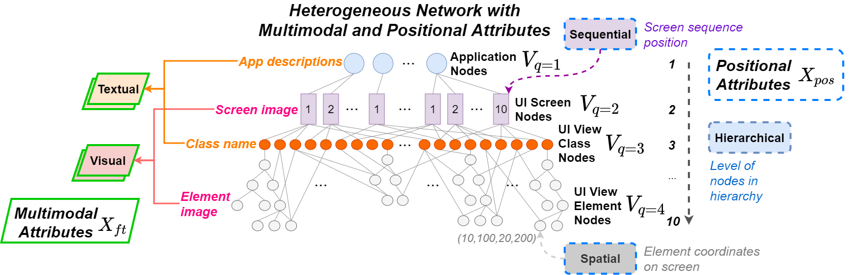
If you look at the figure below (extracted from my recent paper on learning UI design networks), you will see that one can frame UIs as a heterogeneous network. The basic idea is that rich semantic information could be obtained by modelling different types of nodes and edges, each with information or attributes from different modalities, and different positional information. In the figure, you can see that it comprises application nodes, UI screen nodes, UI view class nodes and UI view element nodes, with different types of links between them. The different nodes have different attributes. For example, the descriptions of the application nodes, and the Android UI names of the UI view classes are textual information, while the UI screen images, and the UI element images are visual information. We also have different types of positional information. For example, the UI screens occupy different positions in a sequence of user interactions, while the UI elements have different coordinate positions. We constructed many of such networks from the RICO dataset, by parsing each of them from the application node downwards, all the way to the UI element nodes (this was a very laborious and the not so fun part of this paper).
Why should we do so? What’s the point of learning all these information? Well, we want to learn good representations of UIs that can be utilized in many different tasks.
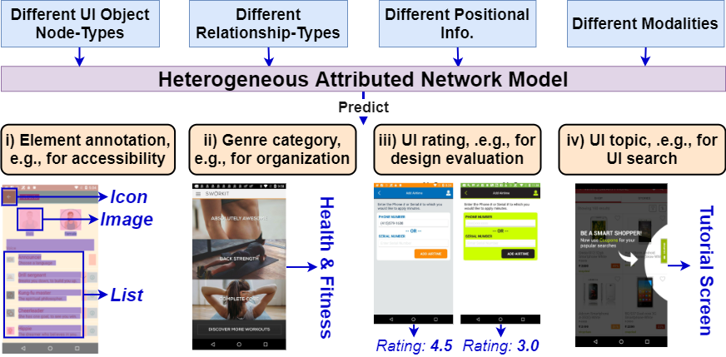
The paper is titled Learning User Interface Semantics from Heterogeneous Networks with Multimodal and Positional Attributes, and is published at the ACM International Conference on Intelligent User Interfaces 2022. If you are curious as to how it works, do read the paper (email me if you cannot get access to the paper via the link). But, in general, the paper proposes a model comprised of 3 main parts that is able to take in such rich network, multimodal, as well as positional information, and used in many different tasks. We learn and combine multimodal (text, visual) information, positional (sequence order, hierarchy level, screen position) information and learn how these information relate to different tasks. We then jointly learn such information with heterogeneous network information and use them for different predictive tasks.

The main inspiration for this paper was an interesting work by Geoffrey Hinton that was published a year ago. The line in Hinton’s paper that motivated my paper is the first line in the introduction – on how people break down visual scenes into part-whole hierarchies when understanding the visual scene.

Basically, it got me thinking about how UI designs can be naturally viewed as part-whole hierarchies. More importantly, it is how the parts fit within the wholes that determine the role of different UI objects and influence how people understand and interact with UIs.
And if you take this line of thought further, it is equally applicable to any type of design or even artwork.